

Table of Contents
Introduction Beginner’s Guide to Scikit-learn
This article is all about Beginner’s Guide to Scikit-learn, Through this blog post, you will be learning one of Python’s most comprehensive libraries built for Machine Learning – the scikit-learn library. If you are skilled in using Python and want to make use of pre-existing features to develop your machine learning model, look no further! Sci-kit learn is a benchmark in terms of A-Z of machine learning algorithms. From feature selection, hyperparameter tuning, and implementing and deploying supervised and unsupervised models – it has it all! You can even bundle up your model into a pipeline and evaluate it using the numerous model metrics.
Industries adopting data science have scikit-learn in their technical stack. Some of the features that make it the best choice for machine learning are –
- Scikit-learn provides a platform to implement various supervised and unsupervised machine learning algorithms via the simple interface of Python.
- It is based on libraries that data scientists frequently use – NumPy, Matplotlib, SciPy, IPython, Pandas etc.
- It is a convenient and proficient tool in terms of data mining and machine learning. With the help of Scikit-learn, one can implement clean and easily reproducible ML algorithms.
- And to hammer the nail on scikit-learn’s robustness, it is widely supported by a myriad of third-party tools which makes it portable and ready to use anywhere.
So whether you are a working professional or simply a beginner to machine learning, don’t fret. Scikit-learn is the building block to a great career in ML applications. Let’s now learn how to install it and some features of the library.
Installation of scikit-learn library
Let’s Start this Beginner’s Guide to Scikit-learn with Installing this all-in-one machine learning package is as easy as pie. If you have either Python 2.7 or Python 3.x, you can install it in one of the following manner. Other prerequisites include NumPy, SciPy and pip.
You can then install scikit-learn by typing the following in the command line.
Using pip
pip install -U scikit-learn
Using conda
conda install scikit-learn
You may also check out their installation page to properly download the library based on your OS config.
Salient Features of the Scikit-learn Library
The scikit learn library focuses on efficiently modeling the data. Let’s look at some important functions that the package provides to develop robust and efficient ML models.
Preprocessing
Most of the data that arrives after mining real-world information cannot be directly used to train a model. A lot of preprocessing and transformation takes place before the data is ready to be trained by a model. The sklearn.preprocessing package provides various utility functions and transformer classes to change raw feature vectors into useful information for estimators. Some important ways data scientists implement data preprocessing are –
- Handling missing values and duplicates – For eg, the SimpleImputer() module fills in missing values by any data that the feature demands.
- Transforming categorical values to a numeric form for efficient training
- Feature extraction − It is the procedure through which the initial raw data is reduced to more manageable groups for processing.
- Feature selection − This involves selecting features that contribute most to the prediction variable. It is vital for supervised machine learning methods.
- Dimensionality Reduction − Transformation of data into lower dimensional space so as to retain only the meaningful attributes of raw data.
Estimators
As we are now aware, the Scitkit-learn library provides a myriad of pre-defined algorithms to perform both supervised and unsupervised machine learning. These are popularly called estimators. The estimator required for your project is largely determined by the data in hand and what outcomes are required. Some widely used estimator models in scikit-learn are –
Supervised Learning algorithms − Popular supervised machine learning models within scikit-learn include:
- Classifiers (ExtraTrees, KNN, Agaboost, and so on),
- Regression (Linear, Logistic)
- Support Vector Machine (SVM),
- Decision Tree, etc.
Unsupervised Learning algorithms − Scikit-learn also includes unsupervised learning algorithms like:
- Clustering (K-means, DBSCAN, Hierarchical…)
- Factor analysis,
- PCA (Principal Component Analysis)
- Neural networks – Restricted Boltzmann Machine
Model Evaluation
No model development can be considered complete without a proper evaluation and performance check. Scikit-learn enjoys the implementation of a large number of statistical metrics based on the estimator model you have picked for your project. This step in the ML development process aims to provide an estimation of how your model works on unseen or unsampled data. All estimators in the scikit-learn library have an inbuilt score() method that returns the default evaluation metric for the respective learning model.
Cross-validation is a technique to check accuracy of supervised models on unseen data. In addition to the basic score() function, the library also boasts of individual metric functions to enable an enhanced evaluation of your model.
For instance, for Linear Regression you can use F1 and RMSE scores to check the performance of your model.
Model Optimization
Machine learning models in the scikit-learn package contain some hyperparameters. These are basically some parameters that either can be manually picked or automatically using inbuilt modules that decide how your model performs. In the data science world, this is known as hyperparameter tuning or optimization. Scikit learn allows optimization using the below methods –
- Ensemble learning: Combines several similar machine learning models to decrease variance and improve predictions – Bagging, Boosting, Stacking
- Grid Search – Uses the GridSearchCV module to search for parameters from the entire model using exhaustive grid search. It is time-consuming but most effective to avoid underfitting the model.
- Randomized Search – Scikit-learn includes the RandomizedSearchCV module to search for hyperparameters using randomized optimization.
Let’s dive into these features by implementing a project
Now in this Beginner’s Guide to Scikit-learn, We will use the publicly available wine dataset to determine the quality of wine.

First we import necessary libraries to load the dataset.
Next we move on to loading the wine dataset and exploring its features.
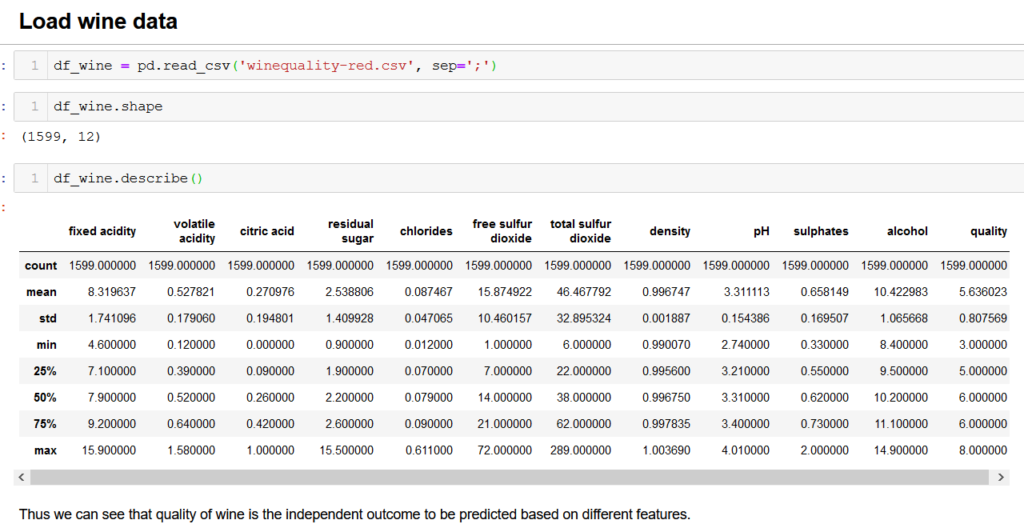
We see that there are numerous characteristics that determine the quality of wine like acidity, pH, sulphates, alcohol content, etc. Quality is the target variable here. This is clearly a supervised learning problem.
Next we check whether there are null values that need to be treated. We also find out the categories in the quality of wine.
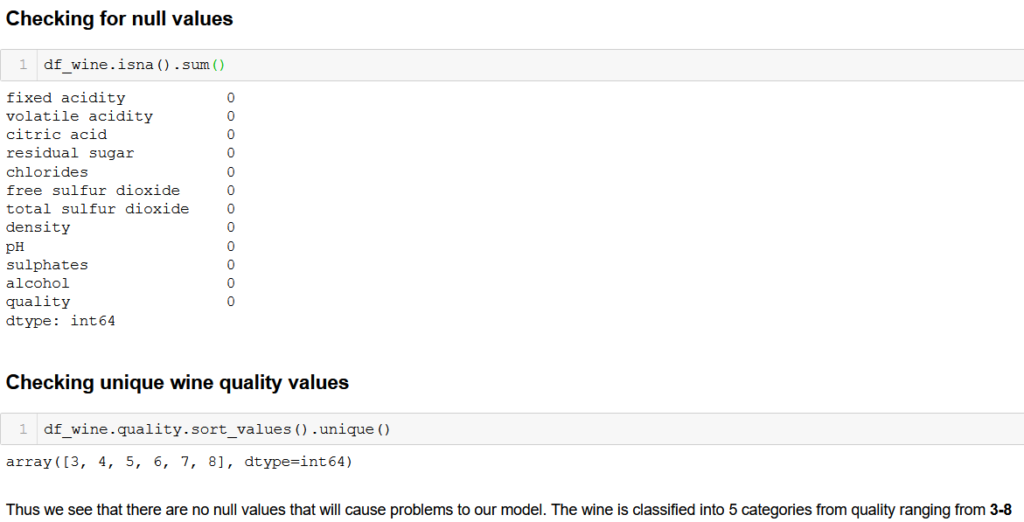
There are no null values to be handles. Furthermore, the quality of wine ranges from 3-8.
Let’s move on to assembling our machine learning model using scikit-learn and discover some of its features. For evaluating the model on the dataset, we first need to split the dataset. In order to do that we separate the independent features and target variable.
We use sklearn.model_selection train_test_split module to automatically create our training and test data.

Let’s now try on some random classifiers before moving on to preprocessing the data. We work on some classifiers available within the sklearn library.

Looks like the Random Forest classifier works slightly better. We have tested the model using the inbuilt scoring technique for each classifier like we mentioned when we discussed the features above. We now move on to preprocessing the data, to check whether this model is overfitted. Preprocessing is also done when data is too large to handle (this isn’t the case here).
Before preprocessing the data, let’s check out the mean and variance of each feature.

Looks like it is not scaled normally. We now apply the Standard Scaling transform on the data to deal with outliers if any. This also transforms our dataframe into a NumPy array for easier manipulation of data. Standardization is a technique that is performed before machine learning models are normally applied. It is done to normalize the range of input representing data characteristics. We split the data again for the model training.

Now, let’s try to choose some optimal parameters for our machine learning model. This is the hyperparameter tuning stage. The hyperparameters basically uphold high-level structural information of our model.
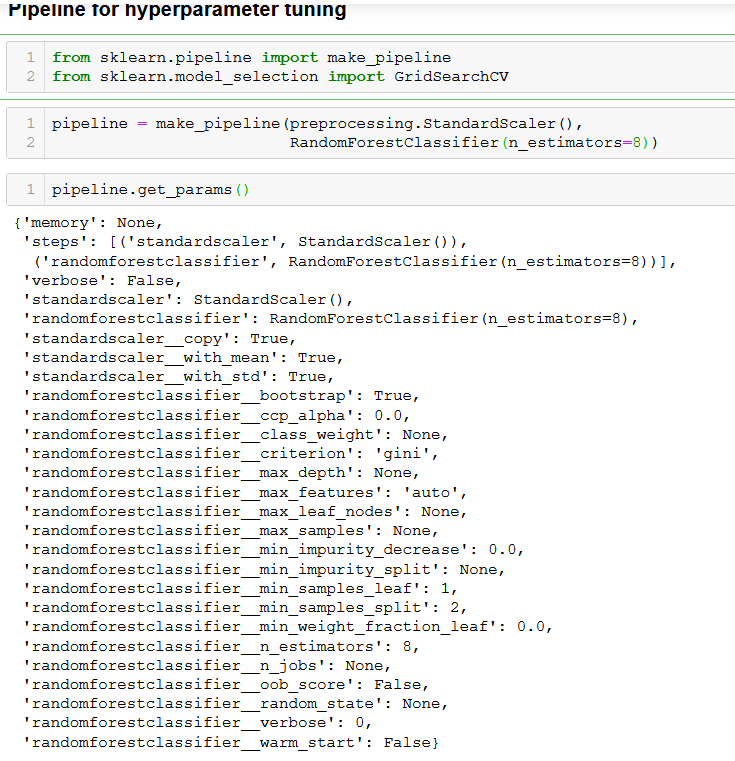
Next we select the hyperparameters we want to tune for performing cross validation of our model.

We now move on to tune our model using the hyperparameters and the pipeline we created. Cross validation is extremely important in order to reduce the possibility of overfitting our model. Suppose we want to tune the maximum depth or the feature of our selected classifier. That’s where cross validation is needed. With this step, we can evaluate our parameters on our training data and estimate the effectiveness.
We can even pass different estimators in our pipeline. Here we use GridSearchCV that performs cross validation on the entire dataset for us.

We can check out the best parameters of our model and the score. Note that the score might have been reduced from earlier. But the cross validation step ensures that the model is no longer at risk of overfitting.
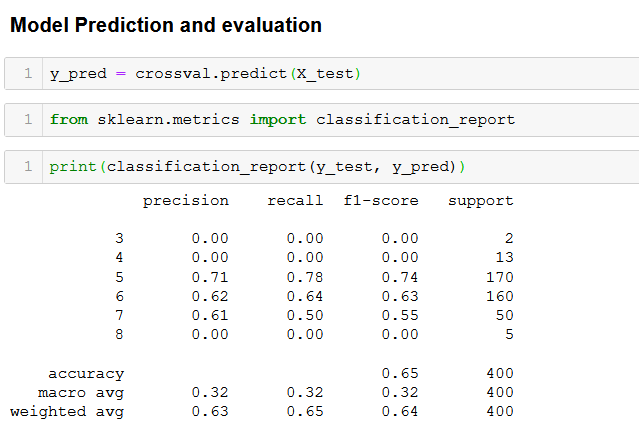
Next, we move on to predict our new values and check out its performance by making use of scikit-learn’s inbuilt evaluation modules.
Lastly, we move on to plot the features that determine the quality of wine according to our cross-validated model.
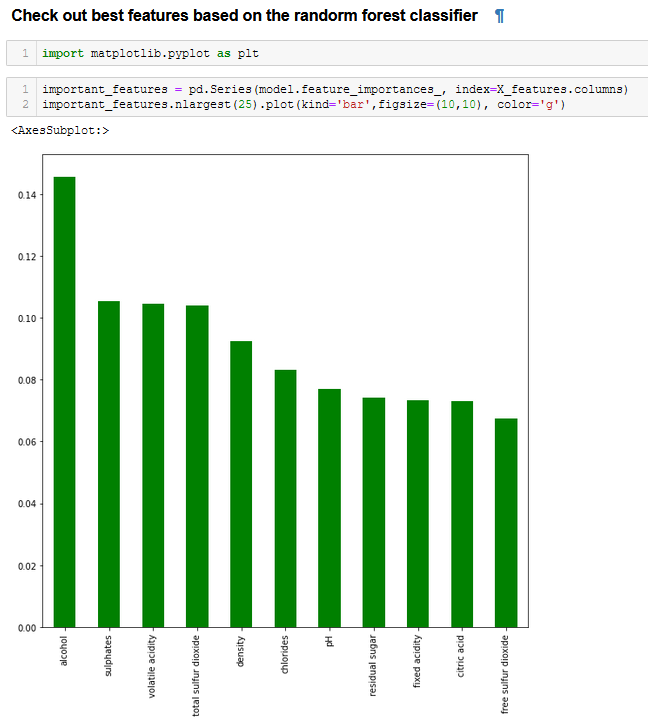
Looks like alcohol content, sulphates and volatile acidity are some important characteristics that determine wine’s quality!
Summary
We hope that you enjoyed Beginner’s Guide to Scikit-learn and working on that dataset. You can now move on to implementing, tuning and deploying your very own machine learning models using scikit-learn. As you have seen, it is extremely beginner-friendly and boasts a wide array of functions at a data scientist’s disposal! Scikit-learn is extremely straightforward to access for model training and predictions. Data science is a vastly evolving domain, and machine learning lies at the crux of it. Make sure you make the most of this easy-to-use machine learning library!


{kind=link}