
Table of Contents
Introduction To Beginner’s Guide to PyCaret
This is Beginner’s Guide to PyCaret. If you’re looking for a beginner-friendly and robust machine learning library, your search ends right here! PyCaret is an open-source ML package in Python that offers a multitude of features. This includes everything ranging from data preparation to model deployment. What makes it impossible to ignore for beginners is that it is a low code. This increases its productivity as data scientists don’t have to stress over the coding aspect. It can be implemented in a notebook of your choice!
PyCaret was developed by data scientist Moez Ali. His ultimate aim was to make machine learning comprehensible and accessible to all – beginners and professionals alike. In this tutorial, we discuss some of PyCaret’s features, how to install the package and implement a simple project with this easy-to-use library.
But before that, let’s move on to elucidate some of PyCaret’s salient features and why data scientists prefer using this library.
Why use PyCaret?
- Let’s start this Beginner’s Guide to PyCaret with why use PyCaret. PyCaret is a machine learning library inspired by R’s caret package. The goal of the caret package is to automate the implementation and evaluation of major classification and regression models in R. PyCaret extends this functionality to Python.
- PyCaret offers automation of crucial machine learning steps by the use of the following components –
- setup() – Used to define the data transforms
- compare_models() – Used to evaluate and compare standard models
- tune_model() – Used for tuning model hyperparameters
- It is easy to use. The library assists in performing end-to-end ML implementations with less coding. It is essentially a Python wrapper around several machine learning frameworks. This includes scikit-learn, XGBoost, LightGBM, spaCy, etc.
- The library is business-ready. It allows quick model prototyping on environments based on the company’s choice. The basic idea was to enable ML by a few data scientists using PyCaret in comparison to a larger team. Thus it is a favorite choice amongst most start-ups.
- PyCaret can be used to implement the following machine learning models –
- Classification
- Regression
- Clustering
- Anomaly Detection
- Natural Language Processing
- Associate Rule Mining

Installing PyCaret
Installing PyCaret is the first step towards building your first machine learning model. Installation is easy and takes only a few minutes. You can install PyCaret using one of the following ways –

Components of PyCaret
| Function | Definition and Use |
| create_model() | It is used to create a model and takes in 1 parameter i.e the Model ID. These include classification, regression, clustering and other models. For eg. lr = create_model(‘lr’) #Here lr is the model ID for logistic regression |
| compare_models() | This function is recommended to be used first for a supervised model. It trains all models using default hyperparameters and evaluates performance metrics using cross-validation. It returns the trained model object. For eg. best_specific = compare_models(include = [‘dt’,’rf’,’xgboost’]) #returns the best model among the 3 mentioned |
| tune_model() | It tunes the hyperparameter of the model passed as an estimator using Random grid search. For supervised learning, this function returns a table with k-fold cross-validated scores of common evaluation metrics along with the trained model object. Whereas, for unsupervised learning, this function only returns the trained model object. For eg. tuned_dt = tune_model(dt, optimize = ‘AUC’) #only returns AUC i.e Accuracy of supervised model |
| ensemble_model() | This function takes in the trained model as the only parameter. For eg. bagged_dt = ensemble_model(dt, method = ‘Bagging’) |
| predict_model() | After a model is deployed or saved, it can be used to predict other data. It takes in data and the model needed to use for prediction. For eg. predictions = predict_model(lr_final, data = data_unseen) |
| plot_model() | Used to analyze a model by visualizing it. For eg. plot_model(lr) #returns a plotted graph |
| finalize_model() | It is used to train the model one last times using all the data including the hold-out. It takes in the trained model and runs it on entire dataset. For eg. final_lr = finalize_model(lr) |
| deploy_model() | Trained models can be used locally by saving it or be deployed on the cloud using AWS. For eg. deploy_model(final_lr, model_name = ‘lr_aws’, platform = ‘aws’, authentication = { ‘bucket’ : ‘pycaret-test’ }) |
Using PyCaret To Classify Loan Applicant Data
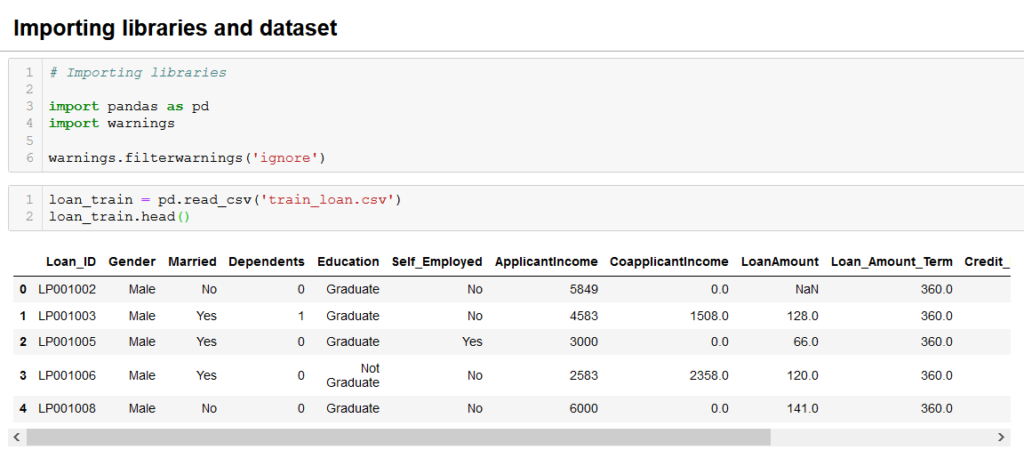
Let’s implement a project now using PyCaret. We first import necessary libraries and datasets.

Next, we import the classification libraries from PyCaret. We can pass the loaded dataset to set up the classification and find out important features. The attribute ‘Loan_Status in this dataset needs to be classified. Thus we pass it as a target.

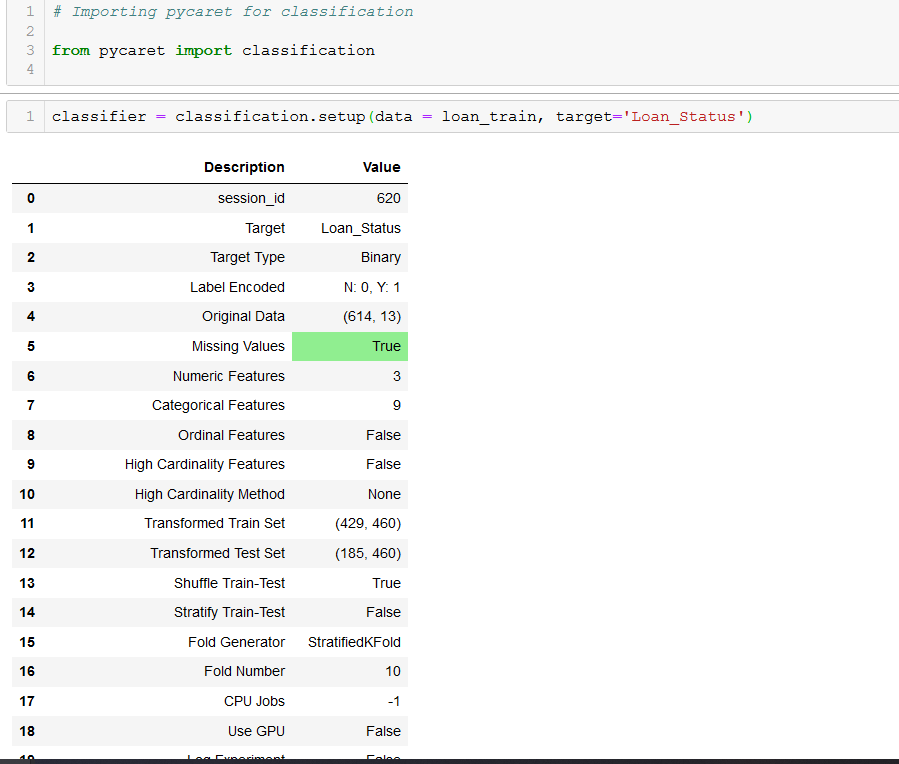
The setup has indicated the presence of null values in the data. How convenient! We can now proceed to check null values. Looks like there are no null values present in important rows especially Loan_Status, so we can proceed.
We can move on to creating some classification models manually. However, there is a function called ‘compare_models()’ to make the task of selecting the model easy for us.

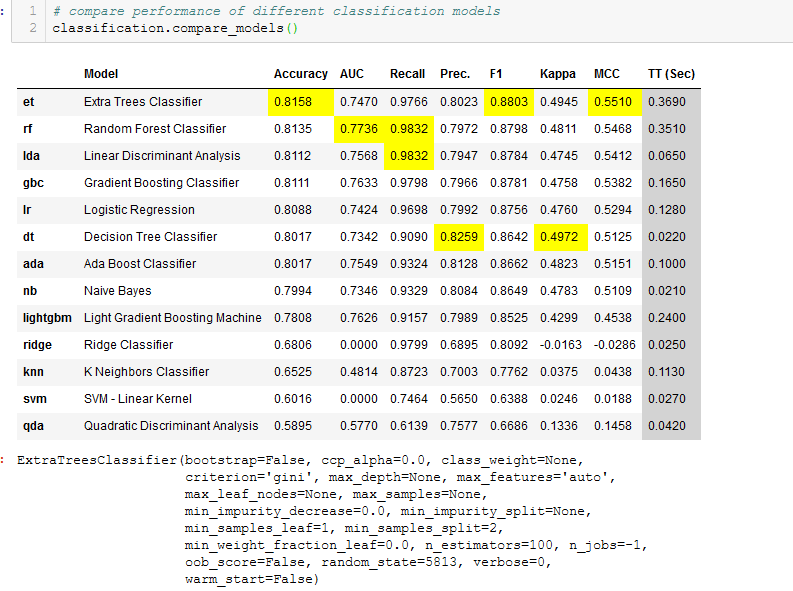
We create the model using this ExtraTreesClassifier.

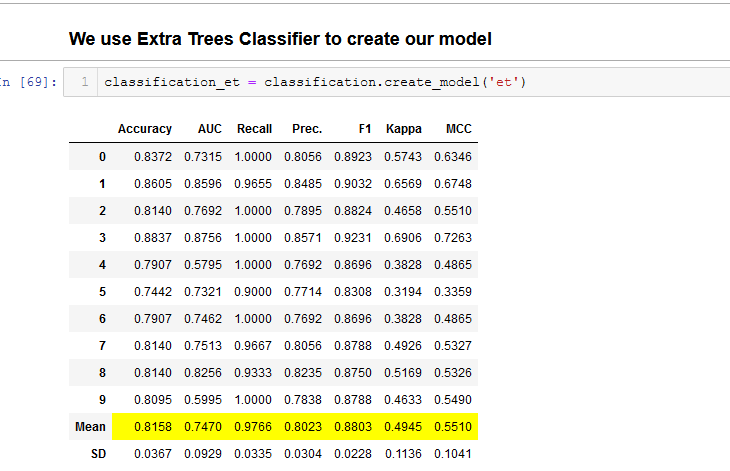
We can evaluate the model to find out important features.

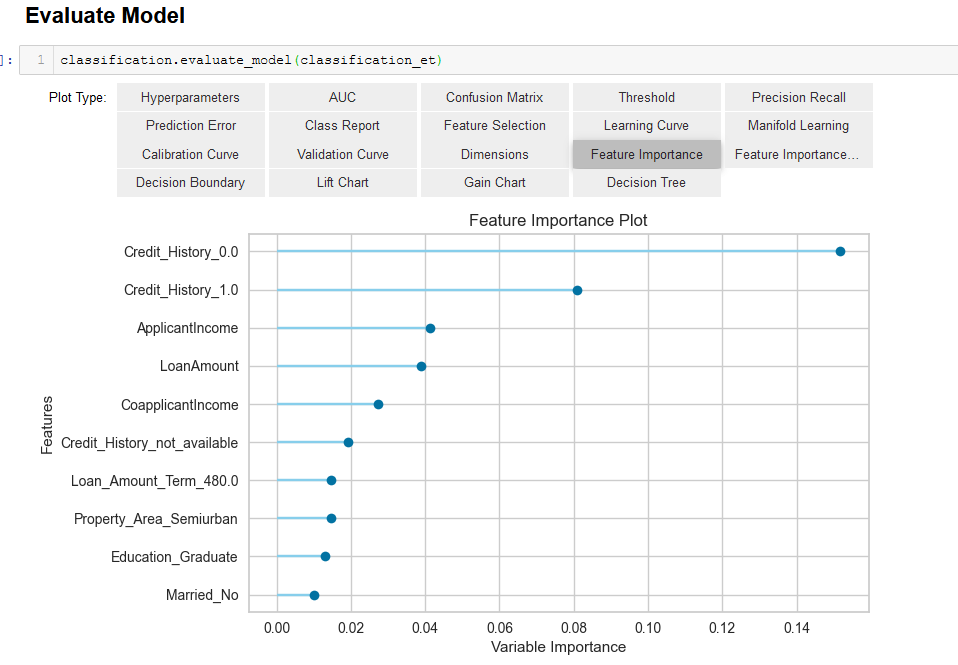
We see that loan amount, applicant income and credit history are some important features that determine loan status. Let’s now run the model on some test data.

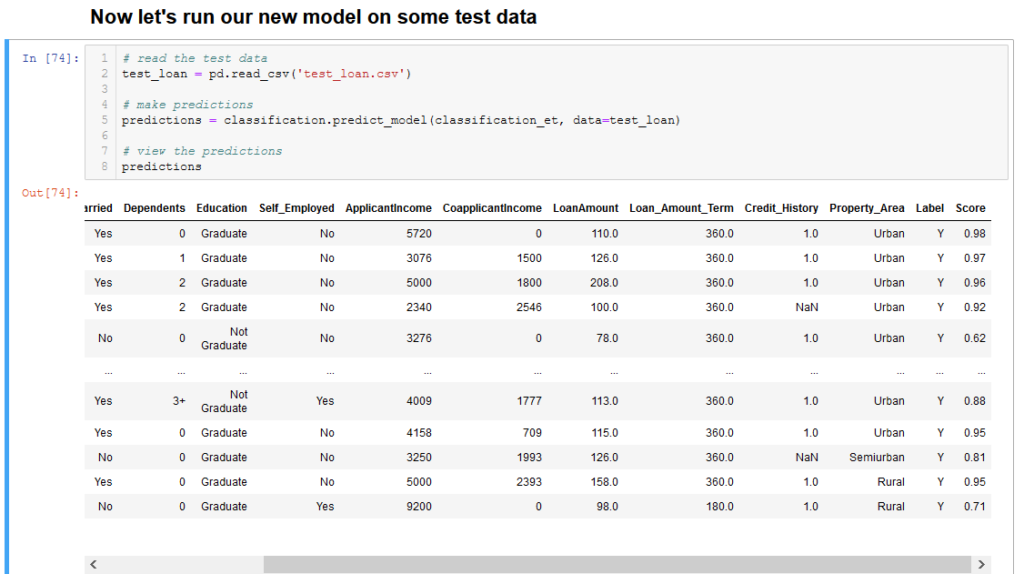
We can see the label and score provided by our model. Thus this model can be used to predict whether loan applicants must be provided a loan by the bank or not.
Next we move on to saving and learning how to load model for future use.

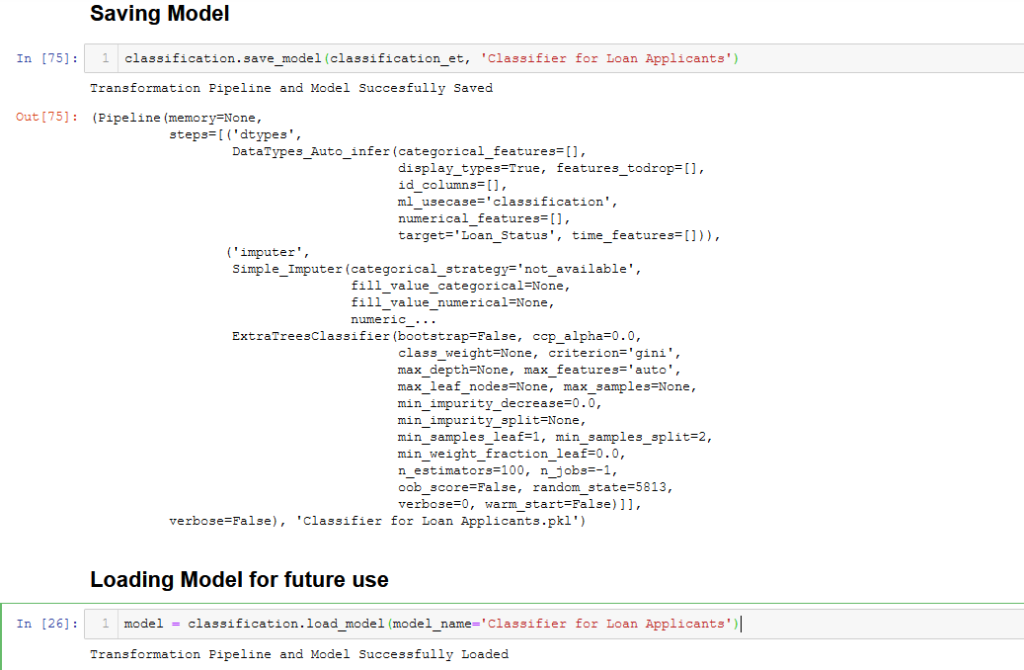
Yay! Our brand new classifier model is ready for use at any time. PyCaret truly makes everything so much simpler!
Summary
Thus through this article we learnt some very interesting features about PyCaret and Beginner’s Guide to PyCaret.
- It is the Python version of the popular and widely used caret machine learning package in R.
- PyCaret can be used to easily evaluate and compare standard machine learning models on a dataset.
- Using PyCaret to easily tune the hyperparameters of a well-performing machine learning model.
- Deploying and saving a model for future predictions.







{kind=link}