

Table of Contents
Introduction Coding the NLP Pipeline in Python
So how do we code this NLP Pipeline in Python? Thanks to amazing python libraries like NLTK (Natural Langauge Toolkit), it’s already done! Another library is there name as spaCy it is also good but NLTK is more powerful. The steps are all coded and ready for you to use.
Install nltk
For notebook
!pip install nltk
After that install the all dependency tool
!pip install nltk(“all‘)
So, let’s explain the step-by-step
Sentence Segmentation
Break the sentence from the text.
import nltk #import library
text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East.” #any text or string
sentences = nltk.sent_tokenize(text) #create a sentence using sent_tokenize
#for output
for sentence in sentences:
print(sentence)
print()
Output:
Backgammon is one of the oldest known board games.
Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East.
Word Tokenization
Word tokenization means seperate the words from sentence.also called as word segmentation.Dividing the string of written language into its words.Use the nltk.word_tokenize function.
for sentence in sentences:
word = nltk.word_tokenize(sentence)
print(word)
print()
Output:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.']
['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.']
Text Lemmatization and Stemming
This is last step of NLP Pipeline in Python. Text lemmatization is used for grammatical reasons. A text can contain different form of a words such as drive,driving,driven,drives,It converts normal form.The main aim of lemmatization and Stemming is to reduce inflectional forms.
Example :- bat,bats,bat’s, => bat
Examples :-the word “better” has “good” as its lemma.the word “play” is the base form for the word “playing”, and hence this is matched in both stemming and lemmatization
from nltk.stem.wordnet import WordNetLemmatizer
lemmaztization = WordNetLemmatizer()
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
word = "mulptiplying"
lemmaztization.lemmatize(word,"v")
Output:
‘mulptiplying’
stemmer.stem(word)
'mulptipli'
Another example using function.
from nltk.stem import PorterStemmer,WordNetLemmatizer
from nltk.corpus import wordnet
def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos):
print("stemmer:", stemmer.stem(word))
print("Lemmatizer:", lemmatizer.lemmatize(word,pos))
print()
lemmatizer = WordNetLemmatizer()
stemmer = PorterStemmer()
compare_stemmer_and_lemmatizer(stemmer,lemmatizer, word = "seen", pos=wordnet.VERB)
Output:
stemmer: seen
Lemmatizer: see
Stop Words
It is called a filtering process. In a text lot of noise. We want to remove this irrelevant noise. The NLTK tool has a predefined list of ‘stopwords’, called ‘corpus’.
nltk.download("stopwords")
once you download we can load the stopwords then import directly from package from
(nltk.corpus).
from nltk.corpus import stopwords
print(stopwords.words("english"))
Output:
"you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Remove the stop words:
stop_words = set(stopwords.words("english"))
sentence = 'Backgammon is one of the oldest known board games.'
words = nltk.word_tokenize(sentence)
print(word)
Output:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.']
without_stop_words = [word for word in words if not word in stop_words]
print(without_stop_words)
Output:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
Remove the stop words:
stop_words = set(stopwords.words("english"))
sentence = 'Backgammon is one of the oldest known board games.'
words = nltk.word_tokenize(sentence)
print(word)
Output:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.']
without_stop_words = [word for word in words if not word in stop_words]
print(without_stop_words)
Output:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
This model is a simple feature extraction technique used when we work with text.Bag of words model based on ‘a vocabulary’ of known words and ‘a measure of the presence’ of known words.
#create a sample text file
with open("text_Sample", "r") as file:
documents = file.read().splitlines()
print(documents)
Output:
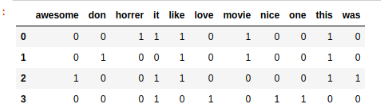
["I like this movie, it's horrer.", "I don't like this movie.", 'This was awesome! I like it.', 'Nice one. I love it.']
#import required library to convert the text into number
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
#design the Vocabulary
count_vectorizer = CountVectorizer()
#Create a bag-of-words
bag_of_words = count_vectorizer.fit_transform(documents)
#bag-of-words model as a pandas Dataframe
feature_names = count_vectorizer.get_feature_names()
pd.DataFrame(bag_of_words.toarray(),columns= feature_names)
Output:







, it’s already done!){kind=link}