

Table of Contents
Introduction to Beginner’s Guide to Python
This is your one-stop place for a Beginner’s Guide to Python. As companies around the globe began to realize the potential of big data for businesses, the need for a dynamic language that could handle this data grew. Data science emerged from this necessity and has become an integral aspect across enterprises. Whether you’re just a beginner into data science or a professional with immense expertise in the field, you know that there is no escaping the marvel of Python. It ticks all the check-boxes as an ideal programming language, being simple and extremely versatile. This object-oriented, high-level programming language has taken over the big data world. Furthermore, it contains efficient semantics and high-level data structures needed for storing data and developing machine learning models.
With this blog post, we will discuss some features of Python that make it exemplary for data science. So what are we waiting for? Let’s dive right in!
Introduction to Python
By definition, Python is an interpreted high-level general-purpose programming language. Its developers emphasized on code readability with its notable use of significant indentation.
In This Beginner’s Guide to Python, As We Know Python is an open-source programming language used in the field of data due to its versatility of functionalities from a mathematical and statistical perspective. It’s a relatively easy programming language to learn and utilize. Furthermore, Python code is generally clean and easy to comprehend. All this makes Python a go-to language especially for beginners in data science.
Being open-source, one can develop their own package and make it accessible to all! It has an excellent community in terms of resources and problem-solving. Its moderate processing speed, accessibility and beginner-friendly syntax have proven to be successful in making it so popular.
Installing Python
Downloading the Python package is extremely simple. Just check out the official downloads page.

Its preferred that you begin using Python 3.x as it is slowly becoming the industry standard. Python 2.x is soon becoming deprecated. Let’s Start This Beginner’s Guide to Python and See Why Python is Most Popular Programming Language in World
Why Python for Data Science?
Python has become a great subject of interest in regard to data science due to its easy learning curve. Let’s now find out about some additional features that make Python worthwhile for this upcoming field.
Syntax
There’s absolutely no denying the sheer simplicity of Python language. This is all thanks to its efficient and intuitive syntax (devoid of those pesky semi-colons, a major win in my book!). Being a high-level programming language, it accomplishes the same tasks with fewer lines of code as compared to other popular programming languages.
Great Data Structures
Python comes equipped with some really powerful data structures. These include lists, dictionaries, and arrays. With the addition of data structures in other libraries like NumPy arrays and pandas dataframes, it is excellent for data storage and manipulation functionalities.
Excellent visualization
Python also supports the creation of graphs and plots for data visualizations. This enables better understanding of data and communication of the insights gained. Matplotlib and seaborn lead the charge for DataViz libraries within Python.
Implementing ML and AI Applications
Developing machine learning models has never been easier, all thanks to Python! Everything ranging from data wrangling, data analysis, model making, model deployment can be covered withing Python. Libraries like scikit-learn are handy for implementing supervised as well as unsupervised machine learning. It doesn’t stop here – Python also supports deep learning applications with the use of TensorFlow and Keras.
Community
Python’s vast community ensures access to a myriad of tutorials, code snippets and error resolution techniques for your code. Read more on How To Start Your Career in Data Science – An Essential Guide
Data Structures for Data Science in Python
Before knowing about the libraries available for implementing your data science project or application, it is important to understand some data structures. They are an essential means of organizing and storing data.
| Data Structure | Definition | Syntax |
| List | Lists are heterogeneous containers of data. They are mutable and are useful in looping and conditional operations. They are enclosed in square brackets []. | 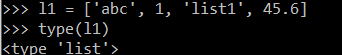 |
| Tuple | Tuples are similar to lists but the values once defined cannot be changes i.e they are immutable. They are computationally faster and take up less memory. They are enclosed with normal brackets (). |   |
| Dictionary | A Python dictionary is a data structure that holds data in the form of key-value pairs. The keys need to be compulsorily unique and unhashable. A dictionary is declared with curly braces {}. |  |
| Numpy array | A numpy array is a grid of values of the same type, and is indexed by a tuple of nonnegative integers. For instance, if you want to convert the aforementioned list ‘l1’ to a numpy array, it will convert it into a string numpy array. |  |
| Pandas Series | Pandas series is a one-dimensional labeled array capable of holding data of any type (integer, string, float, python objects, etc.). The axis labels are collectively called index. | import pandas as pd |
| Pandas Dataframe | Pandas dataframe is a two-dimensional heterogeneous array that is indexed. It is mutable and is the most popular data structure for handling and storing big data. | import pandas as pd |
Useful Data Science Libraries in Python
To make the most out of Python, one must be aware of the myriad of packages and libraries available. Here, we elucidate in brief about some essential Python libraries for data science.
Pandas
Pandas has been specifically designed for efficient and easy data manipulation, wrangling, and aggregation. With its dataframe feature, it is easily one of the best libraries for data analysis. It provides the following features –
- Data preprocessing and cleaning – handling missing and null values, converting data types, etc.
- Data transformation – merge, concatenation, reshaping, slicing, indexing, and many more operations.
- Ability to import data of varied formats – CSV, XLSX, database tables, flat files, and even HTML5!
NumPy & Scipy
NumPy is short for NUMerical PYthon. It is a powerful library specifically designed to work around with multi-dimensional arrays and matrices, called NumPy arrays. They speed up mathematical computations and enable the use of statistical metrics.
SciPy stands for Scientific Python. Another useful library in terms of performing advanced mathematical and scientific calculations. It is especially useful in image processing operations.
Matplotlib & Seaborn
The MAThematical PLOTting LIBrary in Python is extremely beneficial when it comes to data visualizations and easily witnessing various characteristics of data. It is a versatile library that comes with some basic plots like histograms, bar graphs, pie charts, scatter plots, etc.
If you want to take your visualizations a notch further in terms of creativity and additional plots, Seaborn is the way to go. It is built on Matplotlib itself but offers much more. High-level abstractions, multi-plot grids using FacetGrid, observing different distributions, adding color palettes and hues are few features seaborn provides. Furthermore, you can plot a myriad of graphs ranging from violin plots, box plots to cool-looking kernel density estimation (KDE) plots.
You can learn more about both of these libraries in this article – <insert matplotlib and scipy article>
Scikit-learn
Nothing screams machine learning in Python more than than the scikit-learn library. It has gained popularity as being the one-stop for all supervised and unsupervised machine learning algorithms. Scikit-learn is a general-purpose and robust library that not only aids in data modeling, but also supports functions for feature selection and transformations.
Learn more about this library here – <insert sklearn tutorial>
Tensorflow & Keras
Tensorflow is an AI library developed especially for deep learning applications. It is popularly used to develop large-scale neural networks with the help of data flow graphs and layers. Using TensorFlow, one can develop image recognition applications as well as sentiment analysis projects.
Keras is another similar library like Tensorflow. It is used for building and training deep neural network code. Using Keras is however functionally easier and is recommended for beginners into the deep learning.
And thus we come to the end of this Beginner’s Guide to Python, which covers pretty much everything you need to know with respect to data science in Python. In this quick Beginner’s Guide to Python on the efficient Python programming language, we learned why it is so useful for beginners. Of course, there are many other libraries to explore like NLTK for Natural Language Processing or Scrapy for Web Scraping. But this is a good place to start.







{kind=link}