

Table of Contents
Introduction To Statistics in Machine Learning and SciPy
In this article we are going to discuss Statistics in Machine Learning and SciPy, Statistical Machine Learning has become a vital component in the journey to becoming a good Data Scientist. Statistics and other numerical concepts have become an indispensable aspect of Machine Learning. It provides cold, hard, quantitative facts about the data that is being analyzed. Correlations, patterns, covariance, distributions – all are essential to understand the features within your data. Knowing and understanding key statistical concepts is a must-have for anyone beginning their data science journey.
In this blog post, we will learn some important Statistics in Machine Learning and SciPy. We will also study an advanced computational package within Python called SciPy and how it is used to make the most out of raw data.
What is Statistics in Machine Learning and SciPy?
Statistics is a set of analytical methods and tools that help us to answer critical questions about raw data. It is a branch of mathematics used to visualize, analyze and interpret a large set of numbers or a huge sample of observations. In the scope of data science, it is divided into two categories:
- Descriptive Statistics – This type of statistics offers methods to summarize, organize and make sense of data by transforming raw observations into meaningful information that is easy to interpret and share. For instance, finding the average height of the students in a classroom.
- Inferential Statistics – It consists of procedures to study experiments done on small samples of data. This is further used to chalk out inferences for an entire population. It allows researchers to infer or generalize observations of normally large populations. For instance, finding out how much a student may score in a test based on hours studied, attendance, previous scores, etc.
Thus we come to realize that statistics and machine learning go hand in hand for a better understanding of data. Statistical concepts are essential for applied machine learning, as it aids us to select, evaluate and interpret predictive models.
Basic Statistical Concepts
Population: It is a set of resources from which we can acquire information. In other words, it is a group of interest or any group that a researcher wants to learn more about.
Sample: A subset of the population to garner inferential statistics and predict outcomes. It is nothing but a group of data drawn from the aforementioned population.
Variable: A variable can be a quantity, amount or feature that is a descriptive feature of the population.
Types of variables
Variables are broadly divided into two types – qualitative and quantitative. Qualitative variables are those values that can only be represented in textual format. They are also called string variables. Quantitative variables, on the other hand, can be represented using integers/ float.
| Type | Description | Example |
| Discrete | Quantitative variables that are countable over a finite amount of time. | Amount of money spent on groceries every month |
| Continuous | Quantitative data over a continuous span of real data | Weight of a person every day |
| Nominal | Categorical variables that are qualitative | Blood type of a person |
| Ordinal | Represents an ordered series of data or ranked order. The difference between values carries no relevance | Ratings for a service (0-5 stars) |
| Interval | A scale of measure that contains ordered series of data and difference of value carries relevance | Temperature on Celsius scale, credit score, exam scores |
Measures of Central Tendency
Within descriptive statistics, we use certain statistical measures to locate a single score that is the most descriptive of all values in a given population. N here represents the entire population. Measures of central tendency include –
Mean – The arithmetic mean is the average of data at all points. It is computed as:
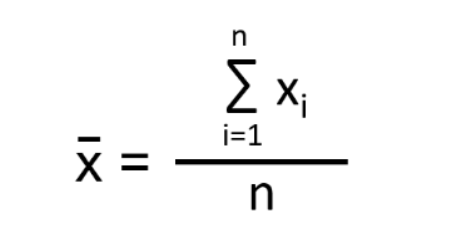
Median – When data is sorted in an ascending order, the median is calculated as the value that lies just in between of this sorted set.

Mode – The mode of a dataset represents that value that occurs most often or most frequently.
Measures of Variability
Range – Difference between the minimum and maximum value in a set of data. Useful when data is devoid of outliers.
Interquartile Range – The difference between the first quartile (Q1) and the third quartile (Q3).
Variance – Measurement of the average squared distance deviation from mean.
Standard deviation – Square root of variance. When data points are closer to mean, the SD is lower. It is always a positive value.
Normal distribution
In statistics and probability, the bell-curve distribution is a popular continuous probability distribution for any arbitrary variable. It is also called Gaussian/ Normal distribution. It focuses on two statistical metrics namely mean and standard deviation. A myriad of natural phenomena are normally distributed, like scores of people in an entrance examination, the height of the population, etc.
Properties of Normal distribution –
- The mean, median, mode are the same.
- While plotted, it represents a bell-shaped curve.
- 68% of data lies within the first SD of the mean.
- Data is symmetrically distributed about the mean.
- The area under the curve represents the probability of the event and is equal to 1.
Hypothesis Testing
Hypothesis testing is a probability-based metric to understand decisions made on experimental data.
- The assumption made for a statistical experiment is called the null hypothesis (H0).
- The alternative hypothesis (H1) contradicts the null hypothesis stating that the assumptions do not hold true at some level of significance.
To determine the effectiveness of our hypothesis, we measure it by using p-values. Some popular hypothesis tests include –
- T-test
- Z-test
- ANOVA (Analysis of Variance)
- Chi-square test
Law of Large Numbers
Just like the concept of Normal distributions is derived from common observations, the law of large numbers is another such naturally observed criterion purely based on numbers. This theorem states that as n (no. of observations) tends to ∞ –

In other words, the Law of Large Numbers (LLN) shows that the average of samples converges to the population/theoretical mean μ (with probability 1) as the sample size increases.
This is anonymous to saying that the more data we collect, the more the data is bound to represent the population respective to the problem domain.
Introduction to SciPy
We now realize how important computing and statistics are for data understanding and research. Sometimes datasets can be gigantic and the need arises to perform mathematical and statistical computations on it. Python has come up with the SciPy library to tackle advanced computational methods.
What is SciPy?
SciPy (Scientific Python) is an open-source logical computing module written in Python. Based on the popularly used NumPy, SciPy includes tools to solve scientific problems. Developers introduced this library to address the growing need to solve complex matters.
While NumPy is a library used for simple numerical computations and calculations, the SciPy library covers more advanced calculations. This niche library comes with additional linear algebra functions and scientific algorithms for data scientists.
Special Packages in SciPy
| scipy.special | Consists of some commonly used computations and algorithms. They are easy to handle since they use numpy arrays as input. For eg. special.factorial, special.perm (permutation), special.comb (combination), special.exp2, special.exp10 |
| scipy.fftpack | Used for discrete fourier transforms needed for image processing |
| scipy.signal | Used for signal processing operations |
| scipy.linalg | This is an important package when it comes to dealing with 2D matrices. We can find the determinant, inverse and eigen values using this package. For eg. linalg.det() , linalg.inv(), linalg.eig() |
| scipy.ndimage | SciPy contains a subpackage for n-dimensional image processing. |
Why statistics is important for data science?
Any company dealing with big data needs their employees to understand the concepts to handle and make the most out of existing data. This is where the statistics and mathematical concepts prove their potential. Understanding data also means making better reports and graphs for future inferences. Some broad areas where statistics come into play in data science are –
- Understanding the data
- Cleaning and processing data (eg. handling missing values by replacing them with measures of central tendency based on the distribution it follows)
- Feature selection and transformation (understanding outliers and how to handle them)
- Model evaluation
- Model prediction
In this article we discussed Beginner’s Guide to Statistics in Machine Learning and SciPy. Thus statistics is an indispensable element of machine learning. Through this article we have covered some most-sought after statistical metrics, although there are many more. We also learn about the SciPy package for complex mathematical computations.







{kind=link}